 逻辑回归
逻辑回归
# 损失函数
损失函数是用来衡量参数θ优劣的评估指标,损失函数小,模型在训练集上表现优异,拟合充分,参数优秀,反之则为糟糕。
注意:没有”求解参数“需求的模型是没有损失函数的,比如KNN和决策树
如,逻辑回归和线性回归,他们都需要求解出一个θ来建立模型,这样的算法才有损失函数,大部分机器学习算法是没有损失函数的。
# PCA / SVD
在逻辑回归中,PCA和SVD一般是不使用的,虽然这两者十分强大,但会将特征的含义彻底抹除,我们可以选用统计方法,但非必要,我们可以将过滤法中提到的诸如卡方、方差、互信息等方法用来特征选择。
# 高效的嵌入法
更有效的特征选择方式应当是嵌入法,由于L1正则化会将特征矩阵的部分参数变为0,因此L1正则化可以用来做特征选择,结合嵌入法的SelectFromModel模块,我们可以容易地筛选出让模型高效的特征。
我们以乳腺癌案例举例
from sklearn.linear_model import LogisticRegression as LR
from sklearn.feature_selection import SelectFromModel
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_breast_cancer
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
data = load_breast_cancer()
LR_ = LR(solver="liblinear",C=0.8,random_state=420)
fullx = []
fsx = []
# 此时,我们使用的判断指标就不是L1范数,而是逻辑回归中的系数了
threshold = np.linspace(0,abs(LR_.fit(data.data,data.target).coef_).max(),20)
k=0
for i in threshold:
x_embedded = SelectFromModel(LR_,threshold=i).fit_transform(data.data,data.target)
fullx.append(cross_val_score(LR_,data.data,data.target,cv=5).mean())
fsx.append(cross_val_score(LR_,x_embedded,data.target,cv=5).mean())
print((threshold[k],x_embedded.shape[1]))
k+=1
plt.figure(figsize=(20,5))
plt.plot(threshold,fullx,label="full")
plt.plot(threshold,fsx,label="Feature selection")
plt.xticks(threshold)
plt.legend()
plt.show()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
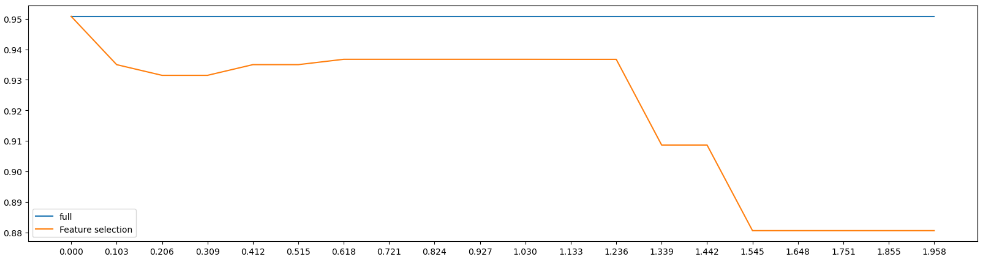
从该案例中可以看到,该案例是在利用学习曲线调整threshold参数,在SelectFromModel中,threshold控制着有多少特征能被保留下来,我们在上述案例中,是以逻辑回归模型中的特征系数为指标进行判断,在乳腺癌案例中共有30个特征,通过np.linspace(0,abs(LR_.fit(data.data,data.target).coef_).max(),20)找出模型中特征系数最大的,然后将[0,最大值]区间等分20份,并建立学习曲线查找最优的threshold,但从结果中可以看到,从0.000~0.103期间,急速下降,兴许我们应该缩小检测范围,即调整参数至[0,0.103]再等分二十份,我们可以得到以下结果。
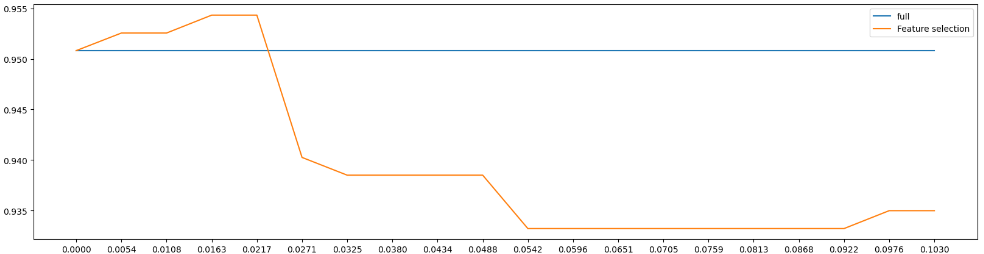 这幅图相比之前结果更加理想,我们能看到,当
这幅图相比之前结果更加理想,我们能看到,当threshold等于0.0163附近时准确率达到最大值,此时的剩余特征为23个,但这个结果真是我们想要的吗?试想一名医生看到23个特征,对于他而言,头都大了,还不如靠以往经验判断。