 特征工程
特征工程
# 3.1 Filter 过滤法
# 方差过滤
VarianceThreshold 通过特征本身的方差来筛选特征的类,比如一个特征本身方差很小,就表示样本在这个特征中... 可能特征中大多数值都一样,甚至整个特征的取值都相同,那这个特征对于样本区分没有价值。 无论接下来的特征工程要做什么,都要优先消除方差为0的特征。
from sklearn.feature_selection import VarianceThreshold
import numpy as np
selector = VarianceThreshold(np.median(x.var().values)) # 实例化,不填参数默认方差为0
x_var0 = selector.fit_transform(x)
x_var0.shape
2
3
4
5
上述代码是一个简单的基于方差中位数进行筛选的案例
方差过滤更好的解释就是一个无视结果好坏的过滤器,他的核心思想是根据预设的阈值进行一刀切,这一刀可能能让模型的结果有正反馈(把噪音切掉了),当然也能让模型有负反馈(把核心特征切掉了),该方法的好处就是降低模型的运行时间(毕竟特征量都减少了)
如果一个特征的方法很小,那么意味着这个特征上很有可能有大量取值相同(例如90%都是1, 10%为0),那这一个特征的取值对于样本而言就没有区分度,这种特征就不带有有效信息,反之,如果方差很大,就意味着带有大量有效信息
# 卡方过滤
这属于相关性过滤,我们希望挑选出与标签相关并且有意义的特征,至于卡方过滤的底层原理不在此说明了,我们提供一个案例用来参考
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.neighbors import KNeighborsClassifier as KNN
from sklearn.model_selection import cross_val_score
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
import numpy as np
x = data.iloc[:,1:]
y = data.iloc[:,0]
x_fsvar = VarianceThreshold(np.median(x.var().values)).fit_transform(x)
cross_val_score(RFC(n_estimators=50,random_state=0),x_fsvar,y,cv=5).mean() #0.9610
x_fschi = SelectKBest(chi2, k=300).fit_transform(x_fsvar,y)
x_fschi.shape # 300
cross_val_score(RFC(n_estimators=50,random_state=0),x_fschi,y,cv=5).mean() #0.956928
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
由于先前方差过滤时,我们得到了一个不错的结果,因此我们在这个案例中可以沿用那个结果,但从上面案例中可以发现,实际上使用卡方过滤后的情况更差了,这是因为卡方过滤把个别关键特征也过滤掉了,那么我们究竟该设置k为多少时比较合适呢?答案是无解。我们需要自己通过学习曲线去分析,得出自认为较好的k的取值
import matplotlib.pyplot as plt
score = []
for i in range(1,201,10):
x_chi = SelectKBest(chi2,k=i).fit_transform(x_fsvar,y)
score.append(cross_val_score(RFC(n_estimators=50,random_state=0),x_chi,y,cv=5).mean())
plt.plot(range(1,201,10),score)
plt.show()
2
3
4
5
6
7
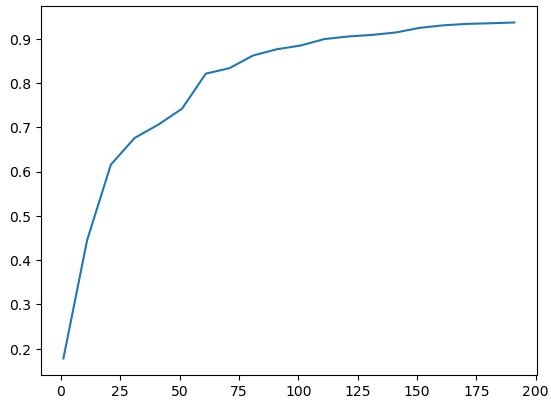 从结果趋势图中看到,随着k值上升,预测值也随之上升,这意味着特征对于训练而言都是有用的。
但学习曲线的成本实在是太大了,需要花费大量时间才能得到一条趋势图,因此我们需要另一种方式更好地确定k值
从结果趋势图中看到,随着k值上升,预测值也随之上升,这意味着特征对于训练而言都是有用的。
但学习曲线的成本实在是太大了,需要花费大量时间才能得到一条趋势图,因此我们需要另一种方式更好地确定k值
| P值 | <=0.05或0.01 | >0.05或0.01 |
|---|---|---|
| 数据差异 | 差异不是自然产生的 | 这些差异是很自然的样本误差 |
| 相关性 | 两组数据是相关的 | 两组数据是相互独立的 |
| 原假设 | 拒绝原假设,接受备择假设 | 接受原假设 |
chivalue, pvalues_chi = chi2(x_fsvar,y)
k = chivalue.shape[0] - (pvalues_chi>0.05).sum()
k # 392
2
3
基于卡方过滤的结论,我们得知,当K=392时,效果最好。
# F检验
F检验,又称ANOVA,方差齐性检验,是用来捕捉每个特征与标签之间的线性关系的过滤方法。
该方法既能做分类也能做回归,因此此包含feature selection.f_classif (F检验分类)和feature_selection.f_regression,其中,F检验分类用于标签是离散型变量的数据,而F检验回归用于标签是连续性变量。和卡方检验一样,这两个类都需要与SelectKBest一起使用,F检验在数据服从正态分布时,效果会很好,因此通常会将数据转换为正态分布的方式。
我们可以用F检验去检测先前得到的结论是否成立。
from sklearn.feature_selection import f_classif
F, pv = f_classif(x_fsvar,y)
k = F.shape[0] - (pv>0.05).sum() # 392
2
3
从上述代码中,我们用F检验再一次得到了相同的结果,这意味着卡方验证的猜想是准确的。
# 互信息法
F检验能够捕捉每个特征与标签之间的线性关系,而互信息法能够捕捉每个特征与标签之间的任意关系(线性/非线性),它可以做回归也能做分类,包含了两个类feature_selection.mutual_info_classif和feature_selection.mutual_info_regression,互相信息法比F检验更加强大。
互信息法不会返回p值或者f值,他会返回“每个特征与目标之间的互信息量的估计”,关系性大则趋于1,反之为0意味着相互独立
from sklearn.feature_selection import mutual_info_classif as MIC
result = MIC(x_fsvar,y)
k = result.shape[0] - sum(result<=0)
k # 392
2
3
4
从互信息法的结论中得出,卡方和F检测的结果是正确的,既然互信息法那么厉害,为什么还要学F检测和卡方呢?因为计算量太庞大了,互信息法一小段数据跑了我2分钟,前两者几乎都是秒出结果。。。
# 3.2 嵌入法
 嵌入法是一种让算法自己决定用哪些特征的方法,即,特征选择和算法训练同时进行,在此期间,各个特征会累计贡献值用于表明该特征对整体的重要性。基于此特性,嵌入法比过滤法更优秀,在性能允许的前提下,可以直接使用嵌入法(你可以理解为,穷人孩子用过滤法手动筛选特征,而富人孩子能用全自动设备自动过滤特征,哭了)
嵌入法是一种让算法自己决定用哪些特征的方法,即,特征选择和算法训练同时进行,在此期间,各个特征会累计贡献值用于表明该特征对整体的重要性。基于此特性,嵌入法比过滤法更优秀,在性能允许的前提下,可以直接使用嵌入法(你可以理解为,穷人孩子用过滤法手动筛选特征,而富人孩子能用全自动设备自动过滤特征,哭了)
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import RandomForestClassifier as RFC
RFC_ = RFC(n_estimators=20,random_state=0)
x_embedded = SelectFromModel(RFC_,threshold=0.00067).fit_transform(x,y)
x_embedded.shape # (42000,284)
cross_val_score(RFC_,x_embedded,y,cv=5).mean() #0.9
2
3
4
5
6
7
# 总结
| 方法 | 描述 | 特性 |
|---|---|---|
| VarianceThreshold | 方差过滤,可输入方差闻值,返回方差大于闯值的新特征矩阵 | 看具体数据究竟是含有更多噪声还是更多有效特征一般就使用0或1来筛选也可以画学习曲线或取中位数跑模型来帮助确认 |
| SelectKBest | 用来选取K个统计量结果最佳的特征,生成符合统计量要求的新特征矩阵 | 看配合使用的统计量 |
| chi2 | 卡方检验,专用于分类算法,捕捉相关性 | 追求p小于显著性水平的特征 |
| f_classif | F检验分类,只能捕捉线性相关性要求数据服从正态分布 | 追求p小于显著性水平的特征 |
| f_regression | F检验回归,只能捕捉线性相关性要求数据服从正态分布 | 追求p小于显著性水平的特征 |
| mutual info classif | 互信息分类,可以捕捉任何相关性不能用于稀疏矩阵 | 追求互信息估计大于0的特征 |
| mutual info_regression | 互信息回归,可以捕捉任何相关性不能用于稀疏矩阵 | 追求互信息估计大于0的特征 |