 卷积神经网络
卷积神经网络
卷积神经网络(ConvNet 或 CNN)更常用于分类和计算机视觉任务。在 CNN 出现之前,人们通常使用耗时的人工特征抽取方法来识别图像中的对象。现在,卷积神经网络提供更加可扩展的方法来执行图像分类和对象识别任务:它们利用线性代数原理(特别是矩阵乘法)来识别图像内的图案。也就是说,它们对计算力的要求可能很高,需要图形处理单元 (GPU) 来训练模型。
# 卷积神经网络如何工作?
卷积神经网络从其他神经网络中脱颖而出的地方在于:它们在图像、语音或音频信号输入方面表现出超级的性能。它们具有三个主要类型的层,分别是:
- 卷积层(提取图像特征)
- 池化层(降维、防止过拟合)
- 全连接 (FC) 层 (输出结果)
卷积层是卷积网络的第一层。虽然卷积层可以后跟另外的卷积层或池化层,但全连接层肯定是最后一层。随着层级的递进,CNN 的复杂性也逐步增加,能够识别图像的更多部分。靠前的层关注于简单的特征,比如颜色和边缘。随着图像数据沿着 CNN 的层级逐渐推进,它开始识别对象中更大的元素或形状,直到最终识别出预期的对象。
# 卷积层
卷积层是 CNN 的核心构建块,负责执行大部分计算。它需要几个组件,包括输入数据、过滤器和特征图。假设输入是彩色图像,由三维的像素矩阵组成。这意味着,输入具有三个维度:高度、宽度和深度,对应于图像中的 RGB。我们还有一个特征检测器,也称为内核或过滤器,它在图像的各个感受野中移动,检查是否存在特征。这个过程称为卷积。
特征检测器是个二维权重数组,表示部分图像。虽然它们的大小可能各不相同,但过滤器大小通常为 3×3 的矩阵;这也决定了感受野的大小。然后,过滤器应用于图像的某个区域,并计算输入像素和过滤器的点积。此点积会进而提供给输出数组。接下来,过滤器移动一个步幅,重复这个过程,直到内核扫描了整个图像。来自输入和过滤器的一系列点积的最终输出称为特征图、激活图或卷积特征。
在每次卷积运算之后,CNN 对特征图应用修正线性单元 (ReLU) 转换,为模型引入非线性特性。
如前所述,初始卷积层可以后跟另一个卷积层。如果是这种情况,CNN 的结构就变成一个分层结构,因为后面层可以看到前面层的感受野中的像素。 例如,假设我们尝试确定图像中是否包含自行车。可将自行车视为各种零件的总和,它由车架、车把、车轮、踏板等组成。自行车的每个零件构成神经网络中一个较低层次的模式,而零件的组合则表示一个较高层次的模式,从而在 CNN 中形成特征层次结构。
# 池化层
池化层也称为下采样层,它执行降维操作,旨在减少输入中参数的数量。与卷积层类似,池化运算让过滤器扫描整个输入,但区别在于,这个过滤器没有权重。内核对感受野中的值应用聚集函数,填充输出数组。有两种主要的池化类型:
- **最大池化:**当过滤器在输入中移动时,它选择具有最大值的像素,将其发送给输出数组。顺便说一句,与平均池化相比,这种方法往往更为常用。
- **平均池化:**当过滤器在输入中移动时,它计算感受野中的平均值,将其发送给输出数组。
虽然池化层中会丢失大量信息,但它还是给 CNN 带来的许多好处。该层有助于降低复杂性、提高效率,并限制过度拟合的风险。
# 全连接层
全连接层的名称恰如其分地描述了它的含义。如前所述,输入图像的像素值并不直接连接到部分连接层的输出层。而在完全连接层中,输出层中的每个节点都直接连接到上一层中的一个节点。
该层根据通过先前层及其不同的过滤器提取的特征,执行分类任务。虽然卷积层和池化层一般使用 ReLu 函数,但完全连接层通常利用 softmax 激活函数对输入进行适当分类,从而产生 0 到 1 之间的概率。
# 卷积神经网络的类型
Kunihiko Fukushima 和 Yann LeCun 分别在 1980 年 (opens new window) (PDF, 1.1 MB)(链接位于 IBM 外部)发表论文和 1989 年发表“反向传播在手写邮政编码识别中的应用”,奠定了卷积神经网络研究的基础。Yann LeCun 更有名,他成功应用反向传播来训练神经网络,以识别一系列手写邮政编码中的图案。在整个 1990 年代,他与自己的团队一起继续开展研究,最终发布“LeNet-5”,将先前研究中的相同原理应用于文档识别。从那之后,随着 MNIST 和 CIFAR-10 等新数据集的推出,以及 ImageNet Large Scale Visual Recognition Challenge (ILSVRC) 等竞争产品的出现,各种不同的 CNN 架构不断涌现。其他一些架构包括:
- AlexNet (opens new window)
- VGGNet (opens new window)
- GoogLeNet (opens new window)
- ResNet (opens new window)
- ZFNet
然而,LeNet-5 被公认为经典的 CNN 架构。
# 卷积神经网络与计算机视觉
卷积神经网络有力地推动了影像识别和计算机视觉任务的执行。计算机视觉 (opens new window)是人工智能 (AI) 的一个领域,让计算机和系统能够从数字图像、视频和其他视觉输入中获取有意义的信息,并根据这些输入采取行动。这种提供建议的能力让它有别于图像识别任务。目前可以看到的计算机视觉的一些常见应用领域包括:
- **营销:**社交媒体平台可以提示谁可能出现在已发布在个人档案中的照片上,从而更轻松地在相册中标记朋友。
- **医疗保健:**计算机视觉已纳入放射学技术,帮助医生在健康的解剖结构中更有效地识别肿瘤。
- **零售:**视觉搜索已纳入一些电子商务平台,帮助品牌企业建议在现有衣橱中补充哪些商品。
- 汽车:虽然无人驾驶汽车时代还未完全到来,但底层技术已开始在汽车中应用:通过车道线检测等功能,提高驾驶员和乘客的安全性。
# 卷积层的扩展理解
卷积运算本质上就是在滤波器和输入数据的局部区域间做点积
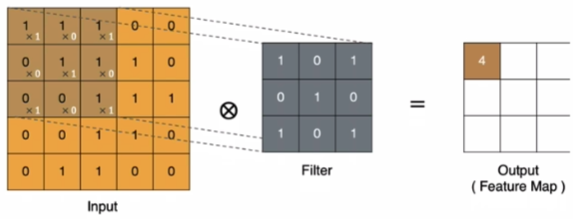 左上角的点计算方法:
$11+10+11+00+11+10+01+00+1*1 = 4$
左上角的点计算方法:
$11+10+11+00+11+10+01+00+1*1 = 4$
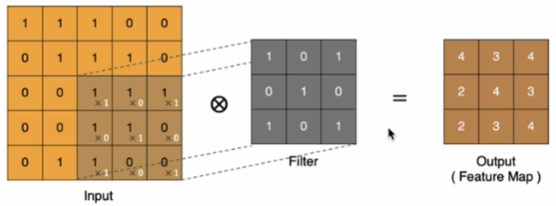
同理可以计算其他各点,得到最终的卷积结果
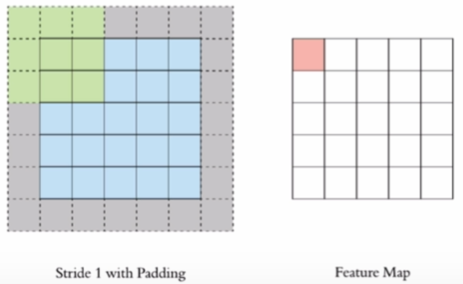
# padding
在上述流程中,特征图相比原图像缩小了一圈,如果我们想保留相同尺寸该如何做呢?
我们可以通过padding来保证尺寸,即在原图像上,添加一圈的0作为扩展,从而保证尺寸
# stride
在上述中,每一步的步长都为1来移动卷积核
 如果我们将stride增大,例如为2,也是可以提取特征图的
如果我们将stride增大,例如为2,也是可以提取特征图的

# 多通道卷积
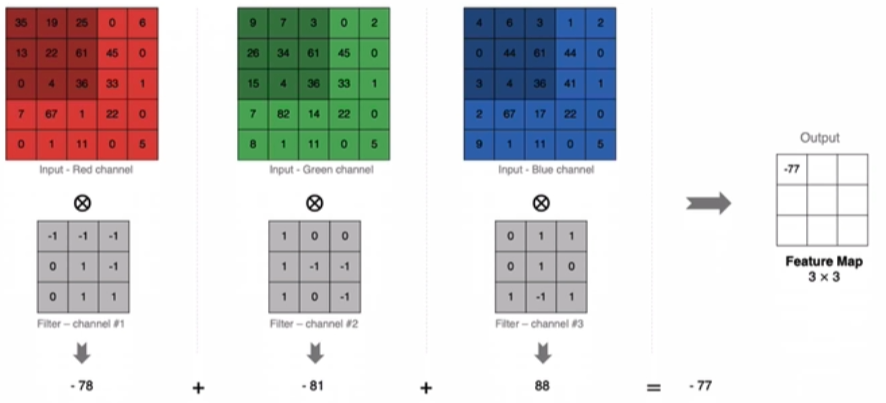
实际中的图像肯定是3通道的,那么我们的filter也会是3通道的
 计算方法如下: 当输入有多个通道 (channel) 时(例如图片可以有 RGB 三个通道),卷积核需要拥有相同的channel数,每个卷积核 channel 与输入层的对应 channel 进行卷积,将每个 channel 的卷积结果按位相加得到最终的 Feature Map
计算方法如下: 当输入有多个通道 (channel) 时(例如图片可以有 RGB 三个通道),卷积核需要拥有相同的channel数,每个卷积核 channel 与输入层的对应 channel 进行卷积,将每个 channel 的卷积结果按位相加得到最终的 Feature Map
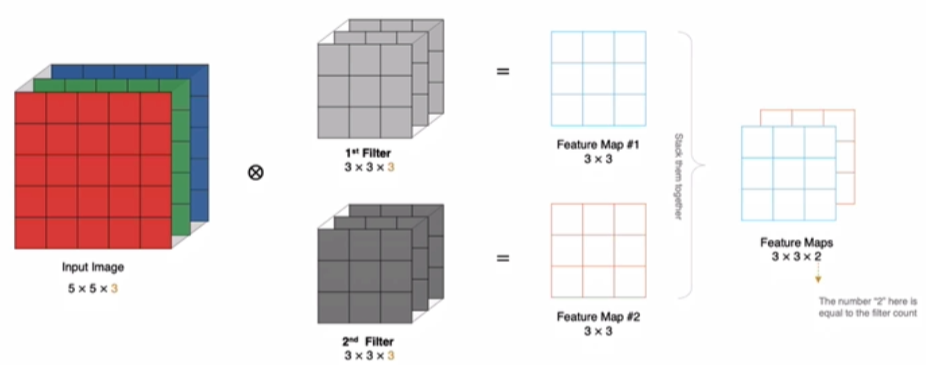
# 多通道多卷积核
如果有多个卷积核时怎么计算呢? 当有多个卷积核时,每个卷积核学习到不同的特征,对应产生包含多个 channel 的 Feature Map,例如下图有两个 flter,所以 output 有两个 channel。
# 计算特征图大小
输出特征图的大小与以下参数息息相关:
- Filter数量K
- Filter大小F
- padding: 零填充P
- stride:步长S
输入特征图为5*5,卷积核为3*3,外加padding为1,则输出尺寸为:(5-3+2*1)/1 + 1 = 5