 正则化
正则化
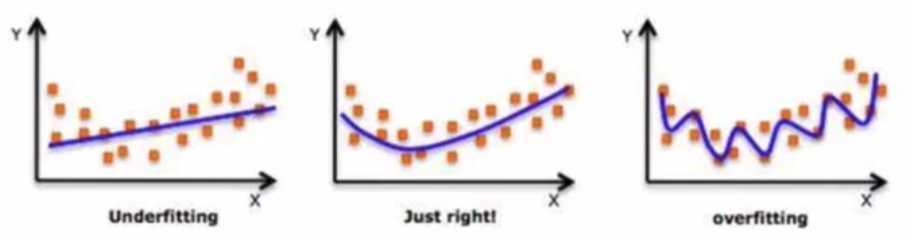 在设计机器学习算法时不仅要求在训练集上误差小,而且希望在新样本上的泛化能力强。许多机器学习算法都采用相关的策略来减小测试误差,这些策略被统称为正则化。因为神经网络的强大的表示能力经常遇到过拟合,所以需要使用不同形式的正则化策略。
在设计机器学习算法时不仅要求在训练集上误差小,而且希望在新样本上的泛化能力强。许多机器学习算法都采用相关的策略来减小测试误差,这些策略被统称为正则化。因为神经网络的强大的表示能力经常遇到过拟合,所以需要使用不同形式的正则化策略。
正则化通过对算法的修改来减少泛化误差,目前在深度学习中使用较多的策略有参数范数惩罚,提前终止,DropOut等,接下来我们对其进行详细的介绍。
# L1 / L2正则化
L1和L2是最常见的正则化方法。它们在损失函数 (cost function)中增加一个正则项,由于添加了这个正则化项,权重矩阵的值减小,因为它假定具有更小权重矩阵的神经网络导致更简单的模型。因此,它也会在一定程度上减少过拟合。然而,这个正则化项在L1和L2中是不同的。
L2 正则化
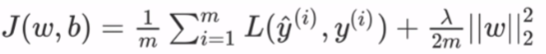 这里的入是正则化参数,它是一个需要优化的超参数。L2正则化又称为权重衰减,因为其导致权重趋向于0 (但不全是0)。
这里的入是正则化参数,它是一个需要优化的超参数。L2正则化又称为权重衰减,因为其导致权重趋向于0 (但不全是0)。tf.keras.regularizers.L2(l2=0.01)L1 正则化
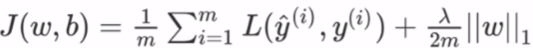 这里,我们惩罚权重矩阵的绝对值。其中,入为正则化参数,是超参数,不同于L2,权重值可能被减少到0.因此,L1对于压缩模型很有用。其它情况下,一般选择优先选择L2正则化。
这里,我们惩罚权重矩阵的绝对值。其中,入为正则化参数,是超参数,不同于L2,权重值可能被减少到0.因此,L1对于压缩模型很有用。其它情况下,一般选择优先选择L2正则化。tf.keras.regularizers.L1(l1=0.01)L1&L2正则化:
tf.keras.regularizers.L1L2(l1=0.0,l2=0.0)
可以在Dense对象的参数中,指明kernel_regularizer=[正则化]即可
# Dropout正则化
dropout是在深度学习领域最常用的正则化技术。Dropout的原理很简单: 假设我们的神经网络结构如下所示,在每个迭代过程中,随机选择某些节点,并且删除前向和后向连接。
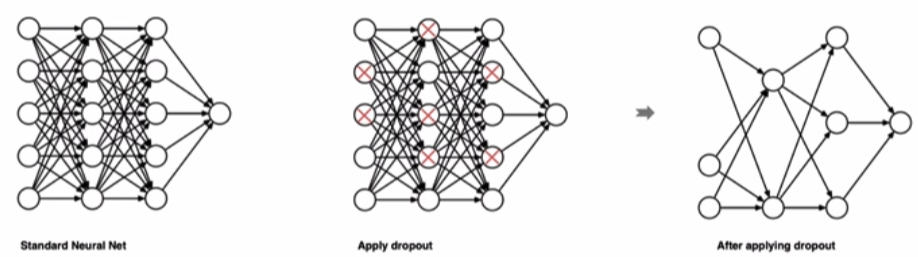 因此,每个迭代过程都会有不同的节点组合,从而导致不同的输出,这可以看成机器学习中的集成方法 (ensemble technique)。集成模型一般优于单一模型,因为它们可以捕获更多的随机性。相似地,dropout使得神经网络模型优于正常的模型。
因此,每个迭代过程都会有不同的节点组合,从而导致不同的输出,这可以看成机器学习中的集成方法 (ensemble technique)。集成模型一般优于单一模型,因为它们可以捕获更多的随机性。相似地,dropout使得神经网络模型优于正常的模型。
在tf.keras中实现,使用的方法是:tf.keras.layers.Dropout(rate=[每个神经元被遗弃的概率])